
L’éditeur d’outils de conception de circuits électroniques et de blocs d'IP Cadence a dévoilé des outils logiciels et une IP de nouvelle génération destinés au domaine de l’intelligence artificielle (IA) afin de répondre à la demande croissante de traitement IA au sein d'objets connectés et d'équipements de périphérie de réseau (edge)
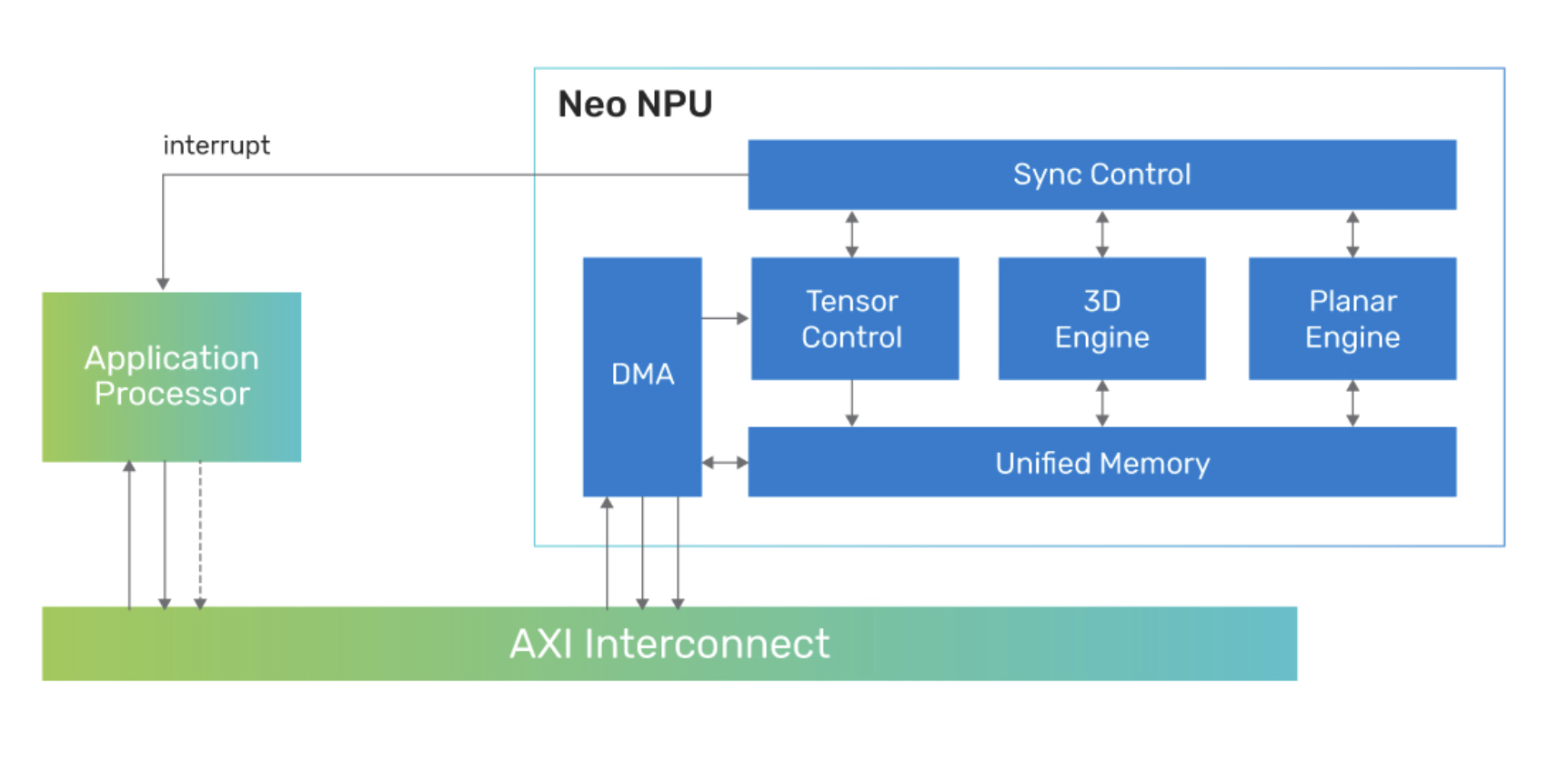
Sous le nom de Neo, la société met à disposition des développeurs des unités de traitement neuronal (NPU, Neural Processing Units) sous forme de blocs d’IP évolutifs dotés d'une gamme étendue de performances IA pour une faible empreinte énergétique, IP destinées à être intégrées dans des puces-systèmes (SoC) dotées de capacités de traitement IA. Ces unités de traitement d’IA affichent une performance de 80 Tops (téraopérations par seconde) par coeur et prennent en charge les modèles d'IA générative. L’idée sous-jacente est de décharger le processeur hôte du SoC de l'exécution des algorithmes IA et ML (Machine Learning), que ce processeur hôte soit un processeur d'application, un microcontrôleur à usage général ou un DSP.
Cadence indique que les performances de l’IP Neo sont jusqu'à 20 fois supérieures à celles de l’IP Cadence AI de première génération, avec 2 à 5 fois plus d'inférences par seconde par surface de silicium (IPS/mm2) et 5 à 10 fois plus d’inférences par seconde par watt (IPS/W).
En complément de cette IP, Cadence propose le kit de développement logiciel IA (SDK, Software Develoment Kit) NeuroWeave qui, dans le même environnement, permet de travailler avec tous les produits IP Cadence AI et Tensilica pour le développement IA "sans code". Cette chaîne d’outils logiciels procure une pile logicielle uniforme, évolutive et configurable pour les DSP et contrôleurs Tensilica, ainsi que les NPU Neo, afin de répondre à toutes les applications ciblées. Le SDK NeuroWeave prend en charge les frameworks ML standard de l'industrie, notamment TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet ou JAX pour la génération automatisée de code de bout en bout, ainsi que les environnements Android Neural Network Compiler, TF Lite Delegates pour l'exécution temps réel et TensorFlow Lite Micro pour les puces de classe microcontrôleur.
« Même si l'attention récente portée à l'IA s'est concentrée dans le cloud, il existe une gamme très étendue de possibilités que l'IA classique et générative peut offrir en périphérie de réseau et au sein des appareils, précise Bob O'Donnell, analyste en chef chez TECHnalysis Research. Du grand public au mobile, de l’automobile à l’entreprise, une nouvelle ère d’appareils intelligents naturellement intuitifs va arriver sur le marché. Et pour que ces projets se concrétisent, les concepteurs de puces et les fabricants ont besoin d'une combinaison de solutions matérielles et logicielles qui leur permettent d'apporter les technologies de l’IA avec des besoins divers en consommation et en performances de calcul, tout en tirant parti d'outils familiers. Les nouvelles architectures de puces optimisées pour accélérer les modèles ML et les outils logiciels avec des liens transparents avec les cadres de développement d'IA populaires joueront à ce niveau un rôle extrêmement important dans ce processus. »
Ainsi, les NPU flexibles Neo conviennent à la conception d'objets ultrasensibles à la consommation ainsi qu'aux systèmes hautes performances dotés d'une architecture configurable, permettant aux architectes de SoC d'intégrer une solution d'inférence IA optimale dans une large gamme de produits : capteurs intelligents, appareils IoT, caméras, appareils auditifs/portables, PC, casques de réalité virtuelle et systèmes avancés d'aide à la conduite (ADAS).
Les IP NPU Neo apportent sur une solution monocœur des performances échelonnables de 8 Gops à 80 Tops avec une extension supplémentaire jusqu’à plusieurs centaines de Tops sur une architecture multicœur. La solution prend en charge de 256 à 32K opérations MAC par cycle, permettant aux architectes SoC d'optimiser leur solution IA embarquée pour trouver le bon équilibre entre consommation, performances et surface de silicium (PPA).
Enfin, Cadence estime que la facilité de déploiement de ces blocs d’IP réduit les délais de mise sur le marché pour répondre à l'évolution rapide des pipelines de calcul dans les systèmes de vision, audio, radar, traitement du langage naturel et d'IA générative. A ce niveau l’IP NPU Neo prend en charge les types de données Int4, Int8, Int16 et FP16 qui constituent la base des réseaux de neurones convolutifs (CNN) et récurrents (RNN).
Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA






 300x250px.png)