
Fournis sous la forme de blocs de propriété intellectuelle à insérer dans des puces-systèmes de type SoC, les FPGA Speedcore de 4e génération de l’américain Achronix délivrent des performances 60% plus rapides que ses prédécesseurs, une consommation d'énergie diminuée de 50% et une empreinte silicum réduite de 65%.... Des caractéristiques qui ouvrent la voie à l’utilisation de ces matrices de FPGA embarquées (avec leurs capacités d'accélération matérielle programmables) pour l'exécution algorithmes d’apprentissage automatique et d’intelligence artificielle gourmands en puissance de calcul. Ou pour les applications de gestion réseau, de stockage dynamique de très grosses masses de données, de gestion de protocoles d'interface…
Achronix a ajouté à la bibliothèque de blocs disponibles au sein de l'architecture Speedcore Gen4, un bloc spécifique qui n'est autre qu'un processeur d'apprentissage automatique MLP (Machine Learning Processor) qui permet, selon Achronix, d’augmenter d’un facteur 3 les performances des applications d'intelligence artificielle. Les blocs MLP sont des moteurs de calcul flexibles, étroitement associés à des mémoires intégrées. Chaque MLP comprend un fichier de registre cyclique local avec une réutilisation optimale des données stockées. Ils sont étroitement associés à des blocs MLP voisins et à des blocs de mémoire incorporés pour délivrer un plus grand nombre d'opérations par seconde, avec une consommation réduite. Ces MLP prennent en charge les formats à virgule fixe et à virgule flottante (Bfloat16, 16 bits, virgule flottante demi-précision, virgule flottante 24 bits et virgule flottante en bloc).
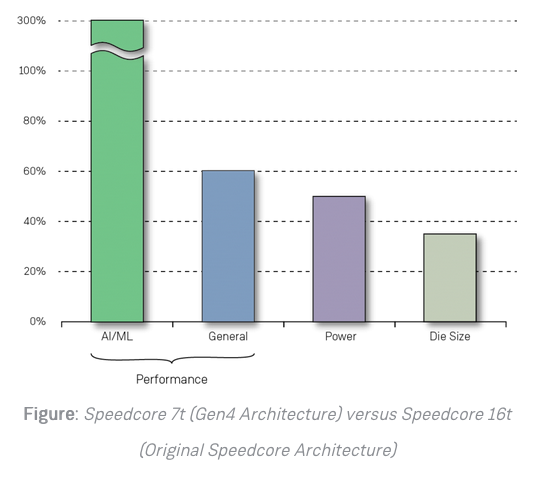 Les utilisateurs peuvent sélectionner à ce niveau l’équilibre optimal performances-consommation-surface de silicium. Pour améliorer encore la densité de calcul, les tables de correspondance LUT (Look-Up Table) des Speedcore Gen4 intègrent des multiplicateurs deux fois plus efficaces que ceux mis en œuvre sur les FPGA classiques, assure Achronix. Ainsi les FPGA classiques du marché mettent en œuvre en moyenne des multiplicateurs 6 x 6 dans 21 tables LUT alors que les Speedcore Gen4 implémentent des multiplicateurs 6 x 6 dans 11 tables LUT avec une vitesse d’exécution jusqu’à 1 GHz. Les modifications apportées à ces blocs FPGA comprennent aussi le doublement de la taille des ALU (Arithmetic Logic Unit), le doublement des registres par LUT, la prise en charge des fonctions 7 bits et de certaines fonctions 8 bits ainsi que des connexions à grande vitesse pour la connexion des registres à décalage.
Les utilisateurs peuvent sélectionner à ce niveau l’équilibre optimal performances-consommation-surface de silicium. Pour améliorer encore la densité de calcul, les tables de correspondance LUT (Look-Up Table) des Speedcore Gen4 intègrent des multiplicateurs deux fois plus efficaces que ceux mis en œuvre sur les FPGA classiques, assure Achronix. Ainsi les FPGA classiques du marché mettent en œuvre en moyenne des multiplicateurs 6 x 6 dans 21 tables LUT alors que les Speedcore Gen4 implémentent des multiplicateurs 6 x 6 dans 11 tables LUT avec une vitesse d’exécution jusqu’à 1 GHz. Les modifications apportées à ces blocs FPGA comprennent aussi le doublement de la taille des ALU (Arithmetic Logic Unit), le doublement des registres par LUT, la prise en charge des fonctions 7 bits et de certaines fonctions 8 bits ainsi que des connexions à grande vitesse pour la connexion des registres à décalage.
L'architecture de routage a également été améliorée avec une structure de bus indépendante fondée sur un multiplexage de plusieurs bus sélectionnables de manière dynamique pour créer un réseau de commutation distribué. Une première, selon Achronix, pour ce type d’architecture.
« Le bloc d’IP Speedcore Gen4 offre une accélération matérielle qui était disponible jusque-là uniquement dans des Asic, commente Robert Blake, CEO d’Achronix. Notre nouvelle architecture ajoute la flexibilité et la reprogrammabilité pour répondre aux demandes liées aux applications d’intelligence artificielle, d’apprentissage automatique et à celles qui réclament des bandes passantes élevées. »
Pour évaluer les cœurs Speedcore Gen4, Achronix propose des outils de conception qui incluent des exemples d’eFPGA Speedcore Gen4 préconfigurés, que les utilisateurs peuvent utiliser pour évaluer les performances en termes d’utilisation de ressources et de temps de compilation.





 300x250px.png)