
Les sociétés Nvidia et ARM ont décidé de collaborer pour apporter l’apprentissage profond (Deep Learning) – et plus particulièrement les moteurs d’inférence – aux futurs équipements mobiles, appareils d’électronique grand public, objets connectés et dispositifs IoT (Internet of Things). ...Ce partenariat, qui va passer par l’intégration de l’architecture open source Deep Learning Accelerator de Nvidia (NVDLA) au sein de la plate-forme d’apprentissage automatique Projet Trillium d’ARM, doit faciliter le travail des fournisseurs de semi-conducteurs qui souhaitent intégrer l’intelligence artificielle au sein de leurs puces-systèmes IoT.
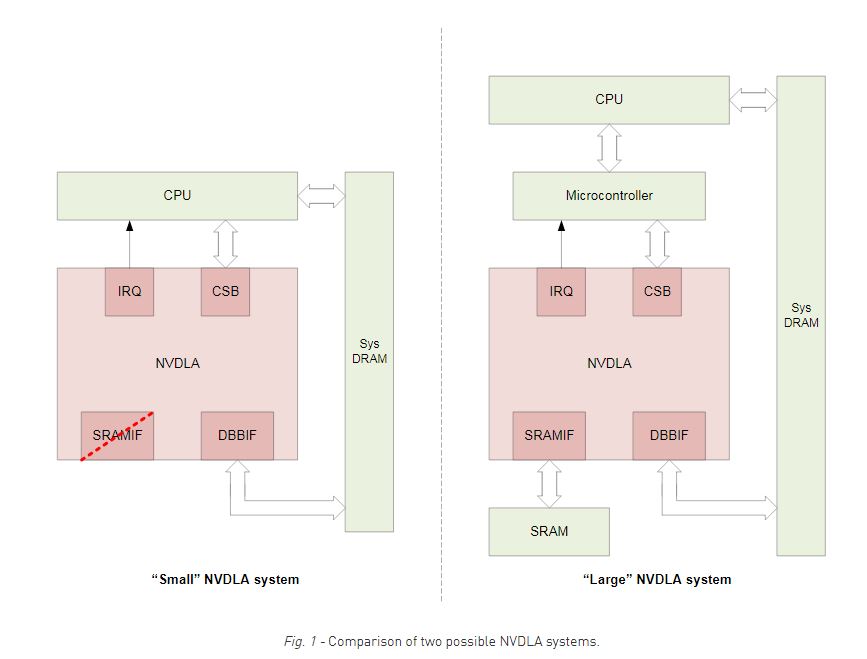
Modulaire et flexible, l’architecture NVDLA, qui a déjà été implémentée dans la puce-système SoC Xavier de Nvidia, associe en pratique matériel et logiciel. De fait, elle se décline en modèles de blocs d’IP qui effectuent les opérations de base de la phase d’inférence de l’apprentissage profond (Convolution Core, Single Data Processor, Planar Data Processor, Channel Data Processor, Dedicated Memory and Data Reshape Engines). Le modèle de simulation et de synthèse Verilog est disponible au format RTL tandis que le modèle de simulation TLM SystemC peut être utilisé pour le développement, l’intégration système et le test. L’écosystème logiciel NVDLA, quant à lui, comprend une pile logicielle (qui fait partie de la version open source), une infrastructure complète d'entraînement pour bâtir de nouveaux modèles d’apprentissage profond et des analyseurs qui convertissent les modèles existants en une forme utilisable par le logiciel embarqué. L’architecture NVDLA est en outre prise en charge par les outils de développement de Nvidia et notamment par les versions à venir de l’outil d’optimisation et d’exécution d’inférences d’apprentissage automatique TensorRT de la société américaine.
De son côté, la plate-forme Projet Trillium, dévoilée en février dernier par ARM, a été présentée par le Britannique comme une suite de blocs d’IP destinés à apporter l’apprentissage automatique et les réseaux de neurones aux terminaux mobiles dans un premier temps, puis aux équipements embarqués (capteurs, enceintes connectées, caméras, produits audio/vidéo grand public, drones, robots, etc.) ultérieurement. On y trouve notamment le processeur ARM ML (Machine Learning) qui, selon la société d’outre-Manche, s’avère capable de développer une puissance de plus de 4,6 trillions d’opérations par seconde (Tops) – un record en la matière – pour une éco-efficacité de plus 3 Tops/W.
« L’accélération des moteurs d’inférence va devenir une fonction de base de tous les dispositifs IoT, assure Deepu Talla, vice-président et directeur général de l’activité Machines autonomes de Nvidia. Notre partenariat avec ARM va doper ce phénomène en permettant à des centaines de sociétés de semi-conducteurs d’intégrer aisément la technologie d’apprentissage profond. » « C’est un partenariat gagnant/gagnant pour les sociétés de semi-conducteurs officiant sur les marchés du mobile, de l’IoT et de l’embarqué qui souhaitent concevoir des solutions d’accélération de fonctions d’intelligence artificielle, commente Karl Freund, analyste de Moor Insights & Strategy. Nvidia mène clairement la danse en matière d’apprentissage automatique tandis qu’ARM est omniprésent dans les nœuds d’extrémité IoT ; cela fait donc sens pour les deux sociétés de s’associer sur le marché des blocs d’IP. »






 300x250px.png)