Avec le processeur Tensilica DNA 100, fourni sous forme d'un bloc d’IP, Cadence renforce de manière significative le niveau de performances et le rendement énergétique de ce cœur de calcul avec l'objectif de favoriser la mise en œuvre d’applications d’intelligence artificielle directement intégrées dans une puce-système SoC. ...Soit dans des systèmes embarqués positionnés au plus près des besoins de traitement en temps réel de masses de données brutes, sans avoir recours à des algorithmes dans le cloud.... Pour, par exemple, l’exécution intégrée de tâches d’inférence dans les applications de vision, de traitement de la parole, de radar, de lidar et de communication.
Afin de s’adapter à ce type d'applications, le processeur DNA 100 affiche selon les configurations de 0,5 à plusieurs centaines de TMAC (Tera Multiply-Accumulate) en termes de performances, ce qui ouvre la voie à l’exécution de tâches d’inférence dans des réseaux de neurones embarqués dans des domaines comme l’automobile, la surveillance, la robotique, les drones, la réalité virtuelle/augmentée, les smartphones, les maisons connectées et l’IoT.
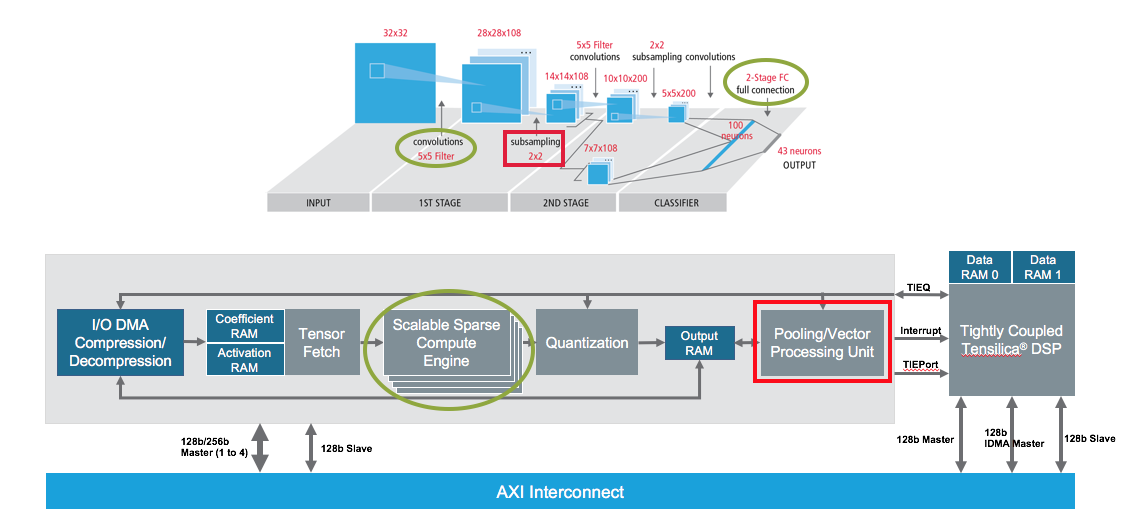
Qualifié par Cadence de premier processeur d’intelligence artificielle fondé sur une technologie d’accélérateur de réseaux de neurones profonds (DNA, Deep Neural-network Accelerator), le DNA 100 exécute des tâches d’inférence au sein de réseaux de neurones en réduisant au maximum les chargements et les multiplications de zéros par les structures de type multiplicateur-accumulateur. Avec à la clé, selon Cadence, des performances jusqu’à 4,7 fois supérieures et un rendement énergétique par watt jusqu’à 2,3 fois supérieur à des solutions similaires fondées sur le même nombre de multiplicateurs-accumulateurs. Le moteur de calcul matériel spécialisé du processeur DNA 100 permet ainsi d’atteindre 2 550 images par seconde (fps) pour une consommation de 3,4 TMAC/watt (en technologie 16 nm), des performances d’inférence estimées sur un réseau neuronal ResNet 50 pour une configuration à 4 000 unités de multiplication-accumulation.
« Les applications pour processeurs d’intelligence artificielle connaissent un essor rapide, mais l’utilisation des réseaux neuronaux les plus récents peut entraîner une augmentation considérable de la consommation d’énergie, précise Mike Demler, analyste au sein du Linley Group. Des architectures plus efficaces sont par conséquent nécessaires pour répondre aux exigences de l’intelligence artificielle utilisée dans de petits capteurs IoT alimentés sur batterie ou des véhicules autonomes. »
Le processeur DNA 100 est livré avec une plate-forme logicielle d’intelligence artificielle et une compatibilité avec la dernière version du compilateur de réseaux de neurones Tensilica qui prend en charge des environnements d’intelligence artificielle avancés, tels que Caffe, TensorFlow et TensorFlow Lite, ainsi qu’un large éventail de réseaux de neurones (y compris les réseaux convolutifs et récurrents). Ce compilateur permet notamment de “mapper” n’importe quel réseau de neurones en un code exécutable et optimisé. Le processeur DNA 100 bénéficie en outre d’un écosystème logiciel existant pour différents types de réseaux (classification, détection d’objets, segmentation, récurrence et régression). Il prend également en charge l’API Android Neural Network (ANN) pour gérer l’inférence d’applications d’intelligence artificielle dans les appareils fonctionnant sous Android.
Plus spécifiquement, l'IP Tensilica DNA 100 peut piloter la totalité des couches des réseaux de neurones : convolutifs, entièrement connectés, récurrents à mémoire court terme et persistante LSTM (Long Short-Term Memory), avec normalisation de réponse locale LRN (Local Response Normalization) et pooling. Un seul processeur DNA 100 peut évoluer de 0,5 à 12 TMAC efficaces selon les besoins en sachant que plusieurs processeurs DNA 100 peuvent être “empilés” pour atteindre des centaines de TMAC dans des applications de réseaux de neurones embarquées gourmandes en puissance de calcul. Le DNA 100 embarque par ailleurs un cœur de DSP de Tensilica qui prend en charge les éventuelles nouvelles couches de réseaux de neurones non encore prises en charge par les moteurs matériels intégrés au processeur DNA 100. Tout en offrant à ce niveau les possibilités de programmation inhérente d’un cœur Tensilica Xtensa grâce aux instructions Tensilica Instruction Extension (TIE). Bénéficiant de son propre DMA (Direct Memory Access), le processeur DNA 100 peut également exécuter d’autres codes de contrôle sans recourir à un contrôleur séparé.
« Les besoins des utilisateurs en matière d’inférence de réseaux de neurones sont multiples et variés, qu’il s’agisse du niveau et de l’ampleur du traitement IA mis en œuvre ou de la diversité des réseaux neuronaux, précise Louis Lazaar, directeur Product Management et Marketing chez Cadence. Or ces mêmes utilisateurs ont besoin d’une architecture évolutive qui soit aussi efficace dans les applications connectées à l’Internet des objets d’entrée de gamme que dans les applications automobiles dont la puissance de calcul doit totaliser 10 voire 100 TMAC. »
La disponibilité du processeur DNA 100 est prévue pour la fin de l’année pour un nombre restreint d’utilisateurs, et pour le 1er trimestre 2019 en volume.