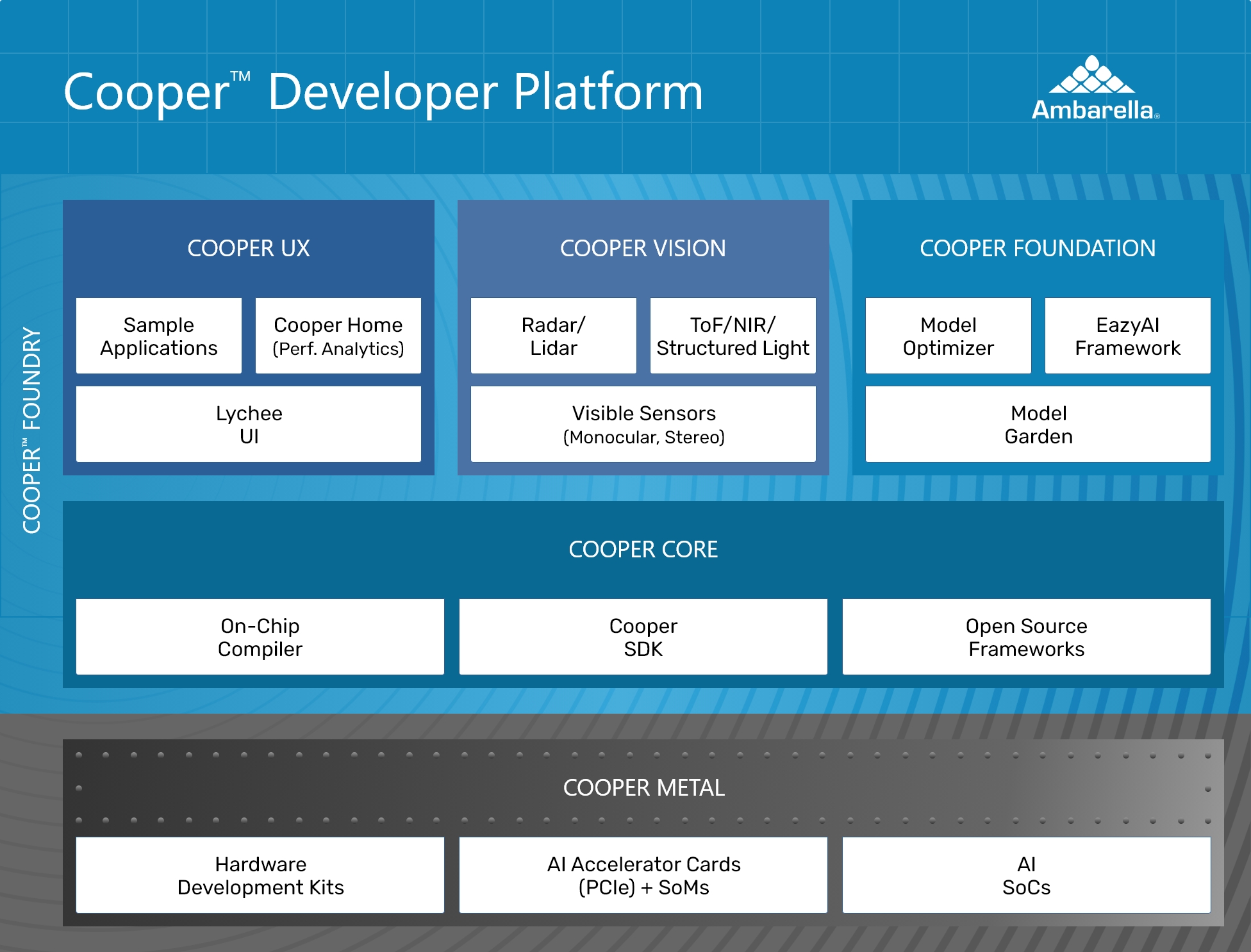
Les puces-systèmes IA à traitement d’image d'Ambarella exécutent des modèles de langage visuel VLM en restant sobres[EDITION ABONNES] Spécialiste des circuits intégrés de traitement vidéo et de vision artificielle à haute résolution et basse consommation, la société Ambarella étoffe son portefeuille de puces-systèmes optimisées par l’intelligence artificielle (IA) avec le modèle 5 nm CV75S. Ce SoC est présenté comme l’option la plus éco-efficace et la plus économique pour exécuter les plus récents des modèles de langage visuel (VLM) multimodaux et réseaux de transformeurs (1) pour le traitement de la vision. Selon Ambarella, l’efficacité de la puce-système met ces technologies IA avancées à la portée d’une large gamme de produits au coût et à la consommation limités : caméras de sécurité pour les entreprises, les villes intelligentes et les magasins de détail, robotique industrielle et contrôle d'accès, appareils vidéo grand public dopés à l’IA comme les caméras de sport et de conférence, etc. « Avec la famille CV75S, nous donnons aux concepteurs de produits grand public la possibilité d'intégrer les dernières technologies de transformeurs de vision en date, et notamment les VLM qui permettent la classification d'images zero-shot (2) et l'inférence multimodale pour une analyse visuelle temps réel sans nécessité d’apprentissage préalable, indique Chris Day, vice-président marketing et business development d’Ambarella. Nous apportons également notre technologie avancée de traitement d’image optimisée par l’IA à des caméras aux prix très divers, pour une qualité d’image nettement supérieure sur un large spectre d’applications. » Un exemple typique de la manière dont le CV75S pourra être utilisé pour exécuter des VLM dans des caméras d'entreprise est une recherche en langage naturel traitée dans la caméra pour rechercher n'importe quel objet ou scène parmi les contenus qu'elle a capturés. Un VLM multimodal, tel que le modèle CLIP (Contrastive Language-Image Pre-Training), peut ainsi parcourir les images et fournir des résultats instantanés sans avoir été "formé" sur cet objet ou ce contexte spécifique. De quoi, selon Ambarella, offrir de nouvelles capacités IA aux caméras d'entreprise qui peuvent désormais exécuter des tâches IA adaptées aux contraintes de leur environnement d’installation et aux besoins des utilisateurs sans avoir à recycler ou à déployer de nouveaux modèles IA pour chaque tâche. Dans la pratique, les puces CV75S constituent la première famille de SoC grand public d'Ambarella à intégrer le moteur d'IA CVflow 3.0, qui offre trois fois plus de performances que la génération précédente avec la prise en charge des VLM et des transformeurs de vision, ainsi qu'un traitement d'image avancé optimisé par l'IA. De plus, les CV75S intègrent la dernière génération en date du processeur d'image (ISP) d'Ambarella, un encodage vidéo 4KP30 H.264/H.265, deux cœurs Arm Cortex-A76 cadencés à 1,6 GHz et une connectivité USB 3.2. Pour accélérer la mise sur le marché, la famille CV75S, actuellement en cours d’échantillonnage, est prise en charge par la plateforme de développement Cooper d'Ambarella, lancée officiellement en janvier lors du CES 2024. Cette plate-forme (voir illustration ci-dessous) fournit les outils de développement matériel (Cooper Metal) et logiciel (Cooper Foundry) nécessaires à la création de systèmes d'IA en périphérie de réseau (edge). Cooper Foundry fournit notamment une pile logicielle multicouche qui prend en charge l’ensemble du portefeuille de SoC IA d’Ambarella. (1) Le transformeur (ou modèle auto-attentif) est une architecture récente d'apprentissage profond qui est principalement utilisée dans le domaine du traitement automatique des langues en servant de base aux grands modèles de langage, mais qui peut aussi servir à traiter d'autres modalités comme les images, les vidéos ou le son, parfois simultanément. (2) L'apprentissage zero-shot est un paradigme d'apprentissage automatique innovant qui répond aux limites des méthodes de classification traditionnelles. En tirant parti de modèles d'apprentissage profond pré-entraînés et de techniques d'apprentissage par transfert, il permet la classification d'images sur des classes invisibles en utilisant les connaissances acquises à partir des classes vues. Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA
|