La puce IA de Flex Logix assure un rapport coût-performances 10 fois meilleur que le Xavier de Nvidia[EDITION ABONNES] Le californien Flex Logix a annoncé il y a quelques jours la disponibilité d’une puce d’inférence IA (intelligence artificielle) pour systèmes de périphérie de réseau (edge) que la jeune société présente comme la plus rapide de l’industrie. ...Référencée InferX X1, cette puce, dont le lancement en production de volume est attendue au cours du deuxième trimestre 2021, vise à accélérer les performances des modèles de réseaux de neurones, tels ceux utilisés dans la détection et la reconnaissance d’objets, dans des domaines comme la robotique, les automatismes industriels, l’imagerie médicale, les véhicules autonomes, l’aérospatial, le commerce de détail, la sécurité bancaire ou le séquençage génétique.
« Les tests de performance de la puce InferX donnent des résultats impressionnants qui dépassent en capacité de traitement ceux des autres produits de sa catégorie, indique Linley Gwennap, analyste pour The Linley Group. L’association de performances éco-efficaces et d’un coût relativement faible devrait séduire les fabricants de systèmes de périphérie intelligents. »
Comme la reconfiguration peut être effectuée en quelques microsecondes, chaque couche d'un modèle de réseau de neurones peut être optimisée avec des chemins de données à pleine vitesse, sachant que dans les réseaux de neurones, chaque couche peut exiger des tailles de données différentes de celles des autres. Dans la technologie Flex Logix, les interconnexions permettent en outre de reconfigurer, à chaque étape, les connexions entre banques d’entrée des mémoires SRam, les grappes de calcul MAC (multiplication-accumulation) et l’activation des banques de sortie mémoire. Le tout se concrétise par un taux d’utilisation des blocs MAC jusqu’à 70% pour des modèles (ou des images) de taille importante, ce qui se traduit par une empreinte silicium et un coût plus faibles, précise Flex Logix. « Dans le domaine des systèmes IA en périphérie de réseau, les utilisateurs souhaitent implémenter des réseaux de neurones dans des applications de plus grand volume, assure Geoff Tate, le CEO et cofondateur de Flex Logix. Notre puce InferX X1 répond à leurs besoins en affichant un rapport coût/performances en inférence de 10 à 100 fois meilleur que celui avancé par le leader actuel du marché. » La société américaine a par ailleurs veillé à ce que ses outils logiciels facilitent l’adoption de son circuit (qui sera aussi disponible dans des versions en gammes de température industrielle et aérospatiale). Ainsi le compilateur InferX accepte pour sa programmation les modèles développés dans les environnements TensorFlow Lite ou ONNX. A noter que Flex Logix compte proposer ses puces sur des cartes aux formats PCIe et M.2 pour faciliter leur intégration dans des passerelles et serveurs de périphérie de réseau. Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA |
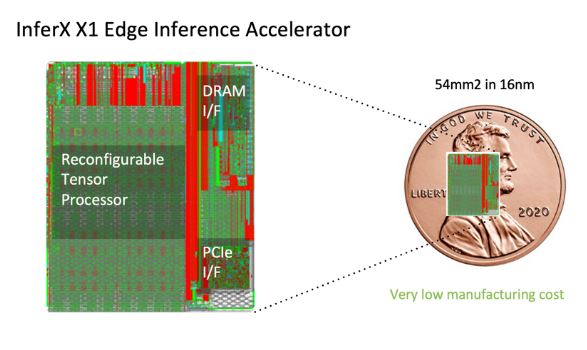 Flex Logix affirme que son circuit exécute l’algorithme de détection et de reconnaissance d’objets Yolov3 30% plus rapidement que la puce-système SoC Jetson Xavier de Nvidia. L’empreinte silicium de la puce InferX X1 est en outre de 54 mm2 seulement (dans un procédé de fabrication 16 nm), à comparer aux 350 mm2 du Xavier, et Flex Logix compte la commercialiser en volume à un coût dix fois inférieur à celui du modèle Xavier NX. Des caractéristiques qui, selon l’Américain, permettraient la mise en œuvre d’inférences IA hautes performances de qualité supérieure dans des produits vendus à des millions d’exemplaires.
Flex Logix affirme que son circuit exécute l’algorithme de détection et de reconnaissance d’objets Yolov3 30% plus rapidement que la puce-système SoC Jetson Xavier de Nvidia. L’empreinte silicium de la puce InferX X1 est en outre de 54 mm2 seulement (dans un procédé de fabrication 16 nm), à comparer aux 350 mm2 du Xavier, et Flex Logix compte la commercialiser en volume à un coût dix fois inférieur à celui du modèle Xavier NX. Des caractéristiques qui, selon l’Américain, permettraient la mise en œuvre d’inférences IA hautes performances de qualité supérieure dans des produits vendus à des millions d’exemplaires.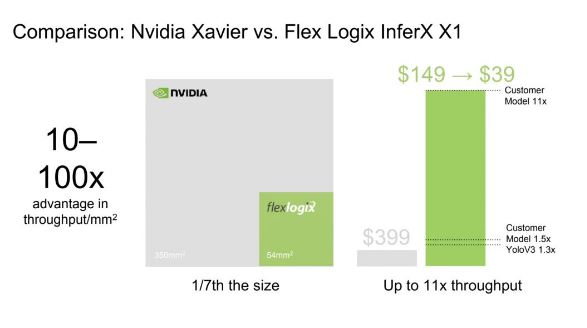 D’un point de vue pratique, le circuit InferX X1 s’appuie sur plusieurs technologies propriétaires de Flex Logix qui améliorent le rapport performances/surface de silicium. Il fait notamment appel à la technologie brevetée d’interconnexion à double densité XFLX que l’Américain utilise dans ses eFPGA (blocs de FPGA intégrables au sein de puces-systèmes et d’Asic) (lire pour plus de détails notre article ici). Cette technologie est associée à un TPU (Tensor Processing Unit) constitué de 64 processeurs Tensor unidimensionnels, étroitement couplés avec de la mémoire SRam, qui sont reconfigurables afin d’implémenter de manière efficace les diverses opérations que nécessite l’exécution des réseaux de neurones. (Ces processeurs se comportent en fait comme un réseau systolique 1D.)
D’un point de vue pratique, le circuit InferX X1 s’appuie sur plusieurs technologies propriétaires de Flex Logix qui améliorent le rapport performances/surface de silicium. Il fait notamment appel à la technologie brevetée d’interconnexion à double densité XFLX que l’Américain utilise dans ses eFPGA (blocs de FPGA intégrables au sein de puces-systèmes et d’Asic) (lire pour plus de détails notre article ici). Cette technologie est associée à un TPU (Tensor Processing Unit) constitué de 64 processeurs Tensor unidimensionnels, étroitement couplés avec de la mémoire SRam, qui sont reconfigurables afin d’implémenter de manière efficace les diverses opérations que nécessite l’exécution des réseaux de neurones. (Ces processeurs se comportent en fait comme un réseau systolique 1D.)