LeapMind veut mettre l’apprentissage profond à la portée des équipements embarqués à basse consommation[EDITION ABONNES] Semaine après semaine, la liste s’allonge des start-up qui conçoivent des processeurs ou des blocs d’IP aptes à traiter des algorithmes d’intelligence artificielle (IA), non plus dans le nuage ou dans des centres de données, mais dans des périphériques en bordure de réseau, voire dans les objets connectés eux-mêmes. ...L’enjeu n’est pas mince. Selon la société d’études Omdia, le marché des puces IA optimisées pour ce marché de "l’edge" devrait atteindre 51,9 milliards de dollars d’ici à 2025, une valeur 6,7 fois supérieure aux ventes de 2019 estimées à 7,7 milliards de dollars. A une liste de jeunes pousses où émargent déjà, entre autres, Ambient Scientific, AnotherBrain, Blaize, BrainChip, Cartesiam, Eta Compute, GML, GreenWaves, Gyrfalcon, Hailo, NeuroBlade, Perceive, Plumerai, Syntiant ou XNOR (récemment racheté par Apple), il faut désormais ajouter le nom de LeapMind. Cette entreprise nippone créée en 2012 s’est spécialisée dans les technologies de quantification sur un nombre de bits extrêmement limité (Extremely Low Bit Quantization) qui permettent de réduire les ressources matérielles exigées par l’apprentissage profond (deep learning). Dans cette optique, LeapMind a récemment annoncé avoir développé une IP d’accélération d’inférence IA à ultrabasse consommation destinée aux concepteurs d’Asic et aux utilisateurs de FPGA. Baptisée Efficiera, cette IP est optimisée pour le traitement des calculs d’inférence sur les réseaux de neurones convolutifs CNN. Si l’on en croit la firme nippone, la technologie de quantification utilisée code les paramètres sur un ou deux bits seulement et ne nécessite pas le recours à des procédés sophistiqués de fabrication de semi-conducteurs ou l’utilisation de bibliothèques de cellules spécialisées pour maximiser l’éco-efficacité et l’empreinte silicium associées aux opérations de convolution (qui représentent l’essentiel du calcul d’inférence).
Dès lors, l’IP Efficiera est censée permettre l’intégration de fonctions d’apprentissage profond dans divers équipements de périphérie de réseau où les critères de consommation et de coût sont critiques, à l’instar des appareils électroménagers, des machines industrielles, des caméras de surveillance, des équipements de diffusion TV ou des robots miniatures. Parmi les applications particulièrement ciblées par LeapMind (voir illustration ci-dessus), on citera la détection des risques de proximité (pour garantir la sécurité autour de machines ou de véhicules industriels en mouvement), le streaming vidéo de haute qualité (pour améliorer l’image en éliminant le bruit sur les images prises en basse luminosité et en bloquant les artefacts générés par les codecs) ou encore le processus de super-résolution (qui consiste à améliorer le niveau de détail d’une image en fonction de la résolution de l’afficheur).
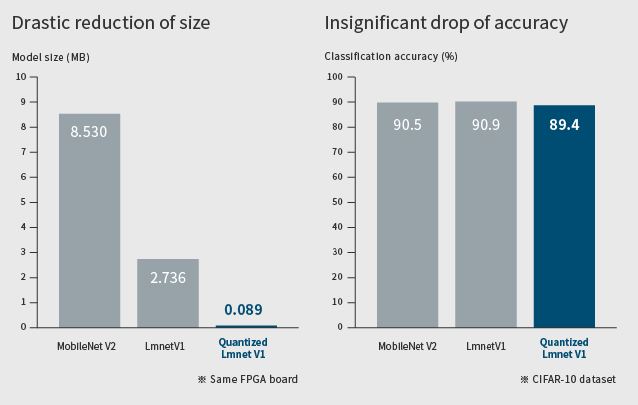
De fait la plupart des réseaux de neurones pour le deep learning codent les poids et les fonctions d’activation sur 16 ou 32 bits (types de données FP16 et FP32) afin d’améliorer la précision des résultats de l’inférence. En contrepartie, ce choix augmente la taille des circuits de calcul (et donc leur empreinte silicium), allonge les temps de traitement et grève la consommation énergétique. Le codage sur un ou deux bits, a contrario, réduit de manière drastique l’empreinte silicium, la complexité de calcul et la consommation… au détriment de la précision.
A noter que LeapMind compte accompagner son IP Efficiera d’un SDK fournissant un environnement d'apprentissage et de développement associé, d’un outil pour l’apprentissage efficace des modèles d'apprentissage profond (Efficiera Deep Learning Model) et d’un service de création de modèles semi-personnalisés spécifiques aux applications reposant sur son savoir-faire technologique (Efficiera Professional Services). Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA |

 Pour rappel, l’apprentissage profond suscite un grand intérêt depuis quelques années car cette technologie améliore la précision de la classification dans plusieurs domaines, y compris le traitement d'image et de flux audio. Elle nécessite toutefois d’importantes ressources de calcul et de mémoire et il est difficile d'effectuer les traitements associés sur des équipements de périphérie de réseau où les contraintes de consommation, de coût et de gestion thermique sont loin d’être négligeables (ce qui n’est pas forcément le cas dans le cloud). LeapMind s’est donc focalisé sur le développement d’une technologie de quantification permettant de réduire la charge des modèles d’apprentissage profond tout en conservant un niveau élevé de précision.
Pour rappel, l’apprentissage profond suscite un grand intérêt depuis quelques années car cette technologie améliore la précision de la classification dans plusieurs domaines, y compris le traitement d'image et de flux audio. Elle nécessite toutefois d’importantes ressources de calcul et de mémoire et il est difficile d'effectuer les traitements associés sur des équipements de périphérie de réseau où les contraintes de consommation, de coût et de gestion thermique sont loin d’être négligeables (ce qui n’est pas forcément le cas dans le cloud). LeapMind s’est donc focalisé sur le développement d’une technologie de quantification permettant de réduire la charge des modèles d’apprentissage profond tout en conservant un niveau élevé de précision.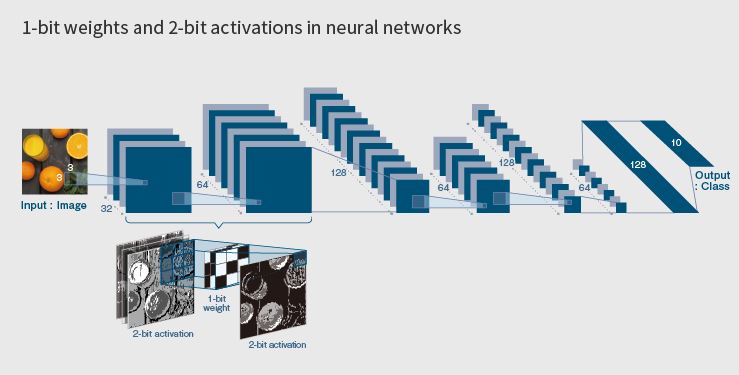 Avec sa technologie Extremely Low Bit Quantization qui code les poids sur 1 bit et les fonctions d’activation sur 2 bits, LeapMind affirme pouvoir maintenir la précision tout en réduisant significativement la taille des modèles et ce en maximisant la vitesse de traitement, l’éco-efficacité et le rapport performances/surface de silicium. En avril dernier, la société a pu avancer des estimations de performances mesurées dans un flot de conception d’Asic avec le concours de la société taïwanaise AIchip Technologies. En utilisant une bibliothèque de cellules TSMC 12 nm, l’IP d’accélération IA du Japonais serait apte à afficher une éco-efficacité de 27,7 Tops/W et une performance de 6,55 Tops à 800 MHz pour une empreinte silicium de 0,442 mm2.
Avec sa technologie Extremely Low Bit Quantization qui code les poids sur 1 bit et les fonctions d’activation sur 2 bits, LeapMind affirme pouvoir maintenir la précision tout en réduisant significativement la taille des modèles et ce en maximisant la vitesse de traitement, l’éco-efficacité et le rapport performances/surface de silicium. En avril dernier, la société a pu avancer des estimations de performances mesurées dans un flot de conception d’Asic avec le concours de la société taïwanaise AIchip Technologies. En utilisant une bibliothèque de cellules TSMC 12 nm, l’IP d’accélération IA du Japonais serait apte à afficher une éco-efficacité de 27,7 Tops/W et une performance de 6,55 Tops à 800 MHz pour une empreinte silicium de 0,442 mm2.