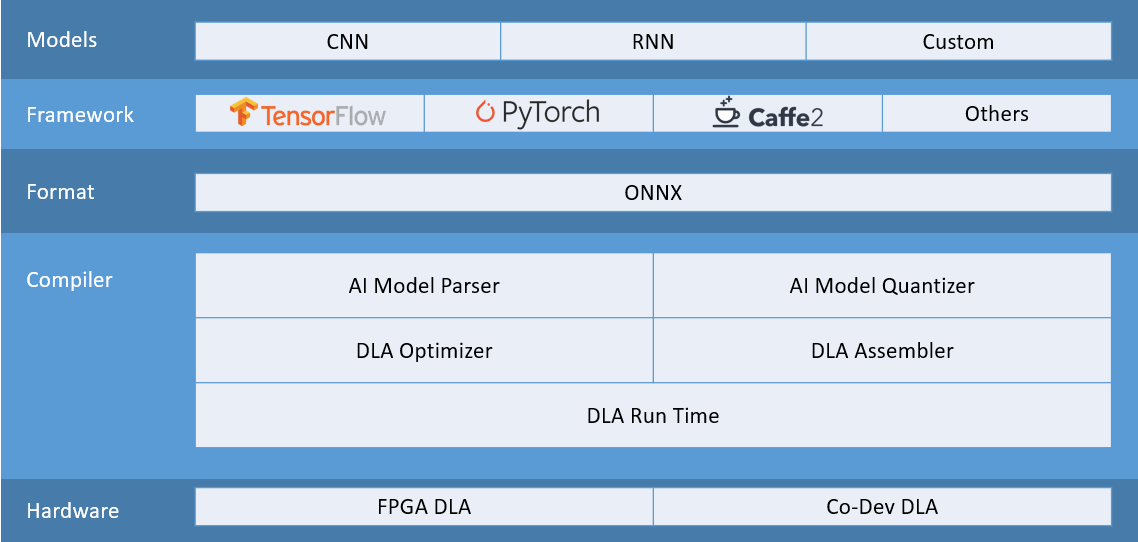
En s’offrant FWDNXT, le fabricant de mémoires Micron aborde l’apprentissage profond pour l’IoT[EDITION ABONNES] Le fabricant américain de mémoires Micron Technology a mis la main pour un montant non dévoilé sur son compatriote FWDNXT (à prononcer Forward Next), une start-up créée en 2017 qui a développé des outils logiciels et matériels pour applications d’apprentissage profond (deep learning). ...Micron compte s’appuyer sur les technologies d’intelligence artificielle (IA) de la jeune société pour commercialiser des solutions requises pour l’analyse de données, notamment sur les marchés de l’Internet des objets et du traitement en périphérie de réseau (edge computing). L’objectif avoué est de combiner ressources de calcul, mémoire, outils et logiciels au sein d’une plate-forme de développement IA qui pourrait en retour fournir à Micron des briques de base pour explorer des architectures mémoire innovantes, éventuellement couplées à des ressources de calcul, et optimisées pour les charges de travail IA. « L’architecture FWDNXT est conçue pour la création rapide de solutions IA en périphérie de réseau grâce à un framework logiciel particulièrement simple à utiliser et à la prise en charge d’un large éventail de modèles IA, indique Sumit Sadana. vice-président exécutif et Chief Business Manager de Micron. L’expertise de FWDNXT en matière de moteurs d’inférence pour apprentissage automatique et d’algorithmes de réseaux de neurones, associée à notre savoir-faire solide dans le domaine des mémoires, va permettre d’atteindre des niveaux inédits de performances et de consommation aptes à satisfaire les applications edge les plus complexes et les plus exigeantes. » Désormais estampillées DLA (Deep Learning Accelerator), les solutions IA de Micron s’appuient sur une architecture matérielle modulaire bâtie sur des FPGA (d’origine Xilinx) et des technologies mémoire de l’Américain où s’exécute le moteur d’inférence haute performance pour réseaux de neurones conçu par FWDNXT. Le kit de développement logiciel SDK associé récupère les fichiers de réseaux de neurones préalablement entraînés au sein de frameworks IA répandus comme PyTorch, Caffe ou TensorFlow et les compile directement sur l’accélérateur, sans que le développeur ait à programmer quoi que ce soit, pour un déploiement rapide du framework à l’application, assure Micron.
|