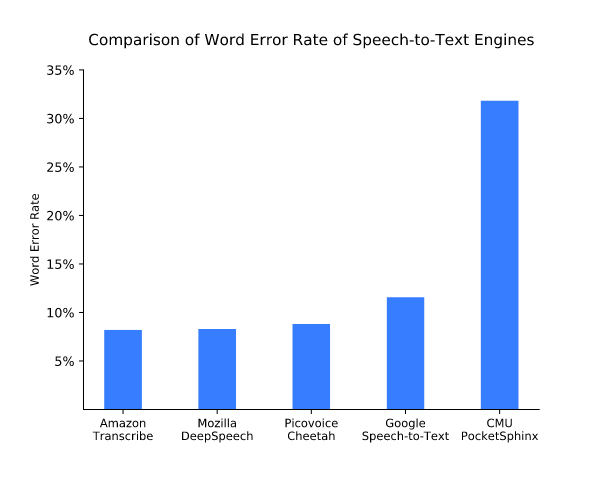
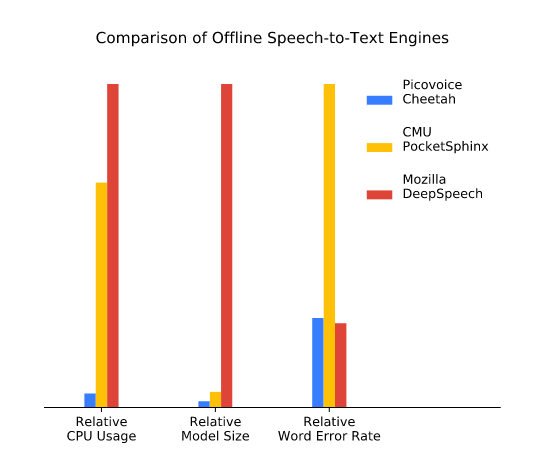
La reconnaissance vocale en local avec la précision du cloud : la promesse de Picovoice[EDITION ABONNES] Depuis leur arrivée sur le marché, les technologies de reconnaissance vocale se sont développées et démocratisées avec la croissance des services vocaux installés dans le cloud. Ce traitement de la parole dans le nuage a entraîné des discussions sur les problèmes de confidentialité générés, ...et sur les limites de cette approche en termes de vitesse de traitement (avec des temps de latence trop longs) et in fine de rentabilité. Dans ce cadre, la reconnaissance vocale en local, hors ligne, peut résoudre ces inconvénients en éliminant le besoin de connectivité et en exploitant des ressources de calcul disponibles sur des milliards de périphériques. Reste que la puissance de calcul nécessaire pour exécuter les algorithmes de reconnaissance vocale demeure importanrte si l’on veut atteindre une précision et une fiabilité élevées. C’est pour répondre à cette problématique que la jeune société canadienne Picovoice (basée à Vancouver) a développé une technologie d’apprentissage profond (deep learning) spécialement conçue pour le speech-to-text, étape essentielle à la reconnaissance vocale, qui permet de traiter efficacement un vocabulaire volumineux sur du matériel standard avec des ressources de calcul limitées. La technologie d’intelligence artificielle vocale de Picovoice est ainsi capable de reconnaître 200 000 mots en temps réel sur une simple plate-forme Raspberry Pi Zero, fondée sur un coeur Arm11. La technologie mise au point par Picovoice s’appuie sur la définition de domaines bien définis dans lesquels l'utilisateur va émettre des commandes parlées. Par exemple, si un utilisateur souhaite créer un réfrigérateur intelligent avec un ensemble défini de commandes vocales, Picovoice forme un modèle pour cette application spécifique, installée sur un simple microcontrôleur. Plus spécifiquement, Picovoice s’appuie sur le jeu d'instructions nécessaire sur la partie audio du périphérique cible (le microcontrôleur) et définit des opérations mathématiques efficaces à mettre en œuvre à l'aide de ces instructions (en fait une opération qui se rapproche de la multiplication de matrices). Ce qui signifie que les modèles formés par Picovoice sont spécifiques à chaque appareil, car dépendant du jeu d'instructions utilisé. Actuellement trois cœurs de processeur sont utilisés au niveau des instructions par Picovoice : Arm, Tensilica HiFi et Ceva TeakLite. Pour illustrer la validité de son approche, Picovoice a comparé la précision de son moteur de speech-to-text par rapport à quatre moteurs largement répandus : Speech-to-Text de Google, Transcribe d’Amazon, DeepSpeech de Mozilla et PocketSphinx de CMU (les données, le code et la configuration du test de référence sont en source ouvert, disponibles auprès de Picovoice). Dans cette étude, on voit que Picovoice atteint une précision comparable aux services en nuage. En outre, les temps d'exécution des moteurs hors ligne sont comparés et Picovoice atteint une précision comparable à celle de Mozilla DeepSpeech tout en étant 23 fois plus rapide et en consommant 53 fois moins de mémoire. Au moment de la réalisation de cette étude, Picovoice souligne que les services de traduction speech-to-text dans le cloud sont facturés au-dessus de 1 dollar par heure, ce qui, selon la société, pour des entreprises qui doivent traiter des millions d’heures d’audio, peut être un coût prohibitif.
|